What We Decided to Analyze and Which Neural Networks We Used
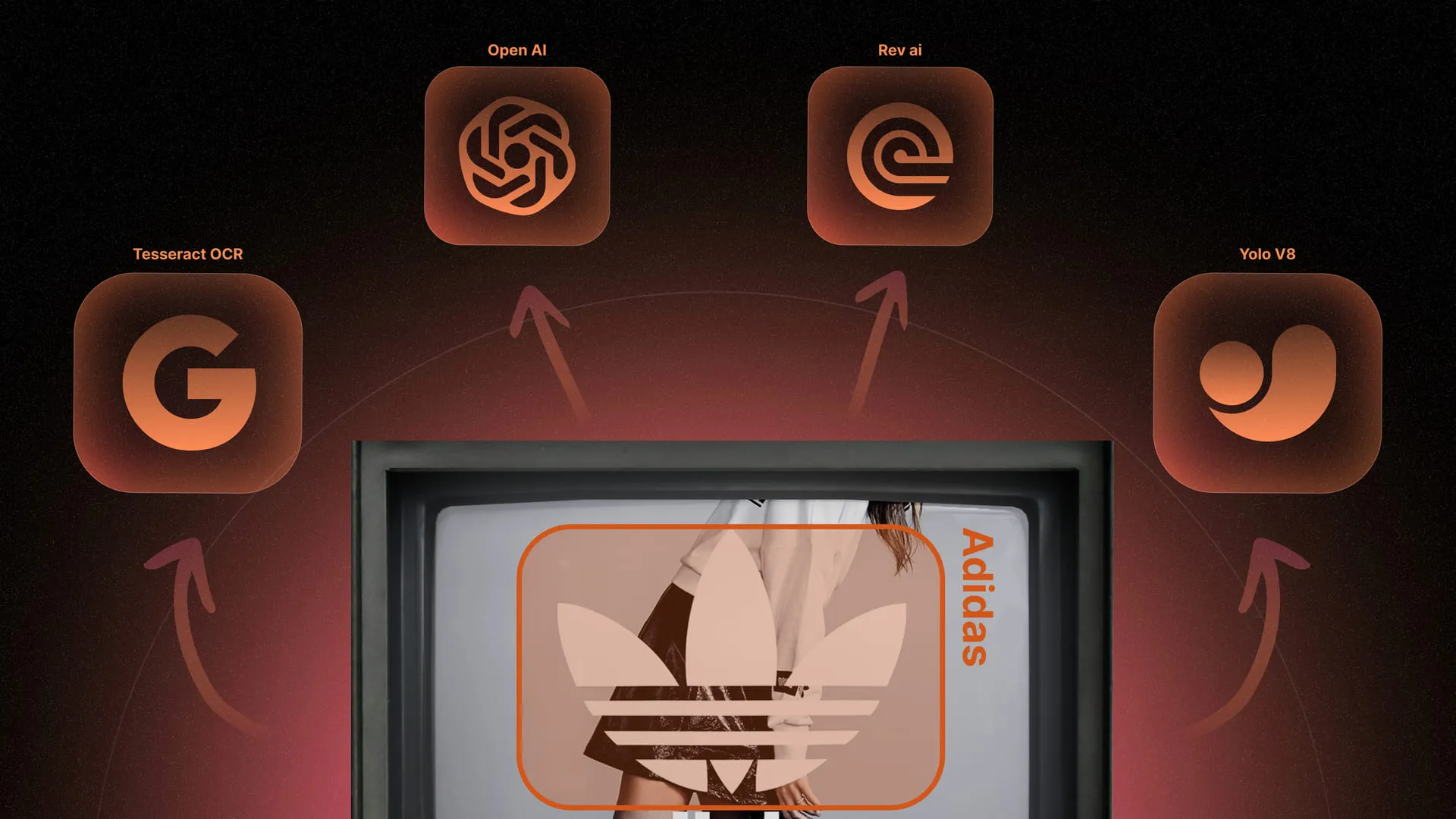
For video content analysis, we integrated five neural networks into the project:
- The first YOLOv8 detects logos.
- The second YOLOv8 identifies common objects (umbrella, ball, person, sneakers, dog, etc.).
- Rev AI transcribes speech and sends the text to ChatGPT.
- ChatGPT extracts mentions of brands, cities, and celebrities from the transcript and determines sentiment (positive/negative attitude of the speaker toward an entity).
- Tesseract recognizes static text within the video frame, such as subtitles, captions, and text-based logos.